Thread Count Scaling Part 3. Zstandard
10 May 2024
Subscribe to my newsletter, support me on Patreon, Github, or by PayPal donation.
This blog is an excerpt from the book. More details in the introduction.
- Part 1: Introduction.
- Part 2: Blender and Clang.
- Part 3: Zstandard (this article).
- Part 4: CloverLeaf and CPython.
- Part 5: Summary.
Zstandard
Next on our list is the Zstandard compression algorithm, or Zstd for short. When compressing data, Zstd divides the input into blocks, and each block can be compressed independently. This means that multiple threads can work on compressing different blocks simultaneously. Although it seems that Zstd should scale well with the number of threads, it doesn’t. Performance scaling stops at around 5 threads, sooner than in the previous two benchmarks. As you will see, the dynamic interaction between Zstd worker threads is quite complicated.
First of all, performance of Zstd depends on the compression level. The higher the compression level, the more compact the result. Lower compression levels provide faster compression, while higher levels yield better compression ratios. In our case study, we used compression level 3 (which is also the default level) since it provides a good trade-off between speed and compression ratio.
Here is the high-level algorithm of Zstd compression:1
- The input file is divided into blocks, whose size depends on the compression level. Each job is responsible for compressing a block of data. When Zstd receives some data to compress, it copies a small chunk into one of its internal buffers and posts a new compression job, which is picked up by one of the worker threads. The main thread fills all input buffers for all its workers and sends them to work in order.
- Jobs are always started in order, but they can be finished in any order. Compression speed can be variable and depends on the data to compress. Some blocks are easier to compress than others.
- After a worker finishes compressing a block, it signals the main thread that the compressed data is ready to be flushed to the output file. The main thread is responsible for flushing the compressed data to the output file. Note that flushing must be done in order, which means that the second job is allowed to be flushed only after the first one is entirely flushed. The main thread can “partially flush” an ongoing job, i.e., it doesn’t have to wait for a job to be completely finished to start flushing it.
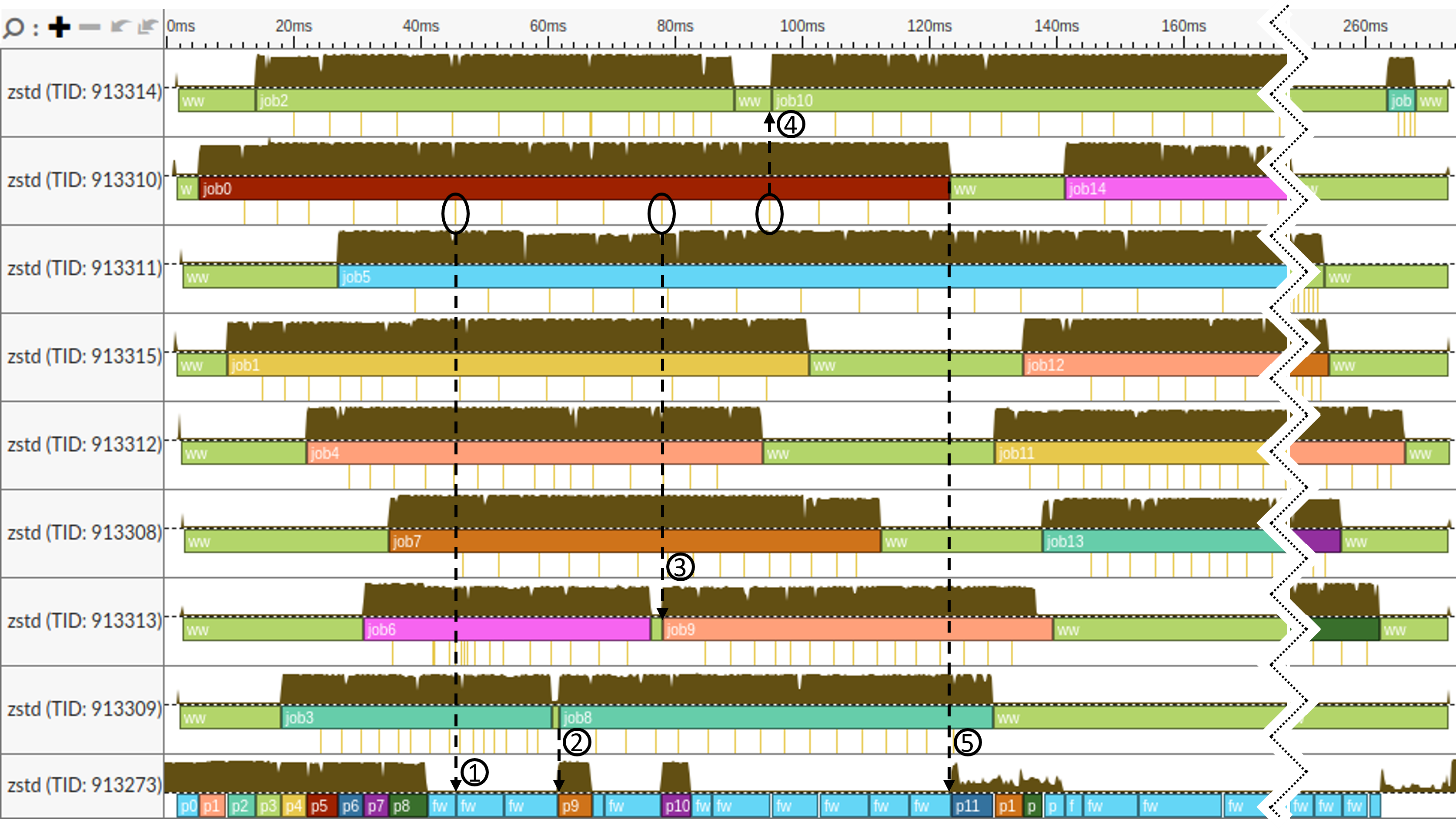
To visualize the work of the Zstd algorithm on a timeline, we instrumented the Zstd source code with Vtune’s ITT markers.2 The timeline of compressing Silesia corpus using 8 threads is shown in Figure 4. Using 8 worker threads is enough to observe thread interaction in Zstd while keeping the image less noisy than when all 16 threads are active. The second half of the timeline was cut to make the image fit on the page.
 |
|---|
| Figure 4. Timeline view of compressing Silesia corpus with Zstandard using 8 threads. |
On the image, we have the main thread at the bottom (TID 913273), and eight worker threads at the top. The worker threads are created at the beginning of the compression process and are reused for multiple compressing jobs.
On the worker thread timeline (top 8 rows) we have the following markers:
- ‘job0’ - ‘job25’ bars indicate the start and end of a job.
- ‘ww’ (short for “worker wait”) bars indicate a period when a worker thread is waiting for a new job.
- Notches below job periods indicate that a thread has just finished compressing a portion of the input block and is signaling to the main thread that the data is available to be partially flushed.
On the main thread timeline (row 9, TID 913273) we have the following markers:
- ‘p0’ - ‘p25’ boxes indicate a period of preparing a new job. It starts when the main thread starts filling up the input buffer until it is full (but this new job is not necessarily posted on the worker queue immediately).
- ‘fw’ (short for “flush wait”) markers indicate a period when the main thread waits for the produced data to start flushing it. During this time, the main thread is blocked.
With a quick glance at the image, we can tell that there are many ww periods when worker threads are waiting. This negatively affects performance of Zstandard compression. Let’s progress through the timeline and try to understand what’s going on.
- First, when worker threads are created, there is no work to do, so they are waiting for the main thread to post a new job.
- Then the main thread starts to fill up the input buffers for the worker threads. It has prepared jobs 0 to 7 (see bars
p0-p7), which were picked up by worker threads immediately. Notice, that the main thread also preparedjob8(p8), but it hasn’t posted it in the worker queue yet. This is because all workers are still busy. - After the main thread has finished
p8, it flushed the data already produced byjob0. Notice, that by this time,job0has already delivered five portions of compressed data (first five notches belowjob0bar). Now, the main thread enters its firstfwperiod and starts to wait for more data fromjob0. - At the timestamp
45ms, one more chunk of compressed data is produced byjob0, and the main thread briefly wakes up to flush it, see (1). After that, it goes to sleep again. Job3is the first to finish, but there is a couple of milliseconds delay before TID 913309 picks up the new job, see (2). This happens becausejob8was not posted in the queue by the main thread. Luckily, the new portion of compressed data comes fromjob0, so the main thread wakes up, flushes it, and notices that there are idle worker threads. So, it postsjob8to the worker queue and starts preparing the next job (p9).- The same thing happens with TID 913313 (3) and TID 913314 (4). But this time the delay is bigger. Interestingly,
job10could have been picked up by either TID 913314 or TID 913312 since they were both idle at the timejob10` was pushed to the job queue. - We should have expected that the main thread would start preparing
job11immediately afterjob10was posted in the queue as it did before. But it didn’t. This happens because there are no available input buffers. We will discuss it in more detail shortly. - Only when
job0finishes, the main thread was able to acquire a new input buffer and start preparingjob11(5).
As we just said, the reason for the 20-40ms delays between jobs is the lack of input buffers, which are required to start preparing a new job. Zstd maintains a single memory pool, which allocates space for both input and output buffers. This memory pool is prone to fragmentation issues, as it has to provide contiguous blocks of memory. When a worker finishes a job, the output buffer is waiting to be flushed, but it still occupies memory. And to start working on another job, it will require another pair of buffers.
Limiting the capacity of the memory pool is a design decision to reduce memory consumption. In the worst case, there could be many “run-away” buffers, left by workers that have completed their jobs very fast, and move on to process the next job; meanwhile, the flush queue is still blocked by one slow job. In such a scenario, the memory consumption would be very high, which is undesirable. However, the downside here is increased wait time between the jobs.
The Zstd compression algorithm is a good example of a complex interaction between threads. It is a good reminder that even if you have a parallelizable workload, performance of your application can be limited by the synchronization between threads and resource availability.
-> part 4
-
Huge thanks to Yann Collet, the author of Zstandard, for providing us with the information about the internal workings of Zstandard. ↩
-
VTune ITT instrumentation - https://www.intel.com/content/www/us/en/docs/vtune-profiler/user-guide/2023-1/instrumenting-your-application.html ↩
All content on Easyperf blog is licensed under a Creative Commons Attribution 4.0 International License