Guest post: COZ vs Sampling Profilers.
26 Feb 2020 by Mark Dawson
Subscribe to my newsletter, support me on Patreon or by PayPal donation.
This is a guest post by Mark Dawson:
Mark E. Dawson, Jr. is a Sr. Performance Engineer with more than 10 years of experience in systems architecture and low-latency development in the FinTech industry. He enjoys boxing in his spare time at the famed Windy City Boxing Gym and is an avid fan of the Wu Tang Clan.
As Denis alluded to in his article “Performance Analysis of Multithreaded Applications”, profiling a multithreaded application is not as straightforward as doing so with a single-threaded one – its single flow of execution through the CPU microarchitecture can be traced intuitively and have its chokepoints identified clearly, lending itself well to a Top Down Mental Model. However, for multithreaded software where multiple flows execute concurrently, the choke point(s) in any given thread’s flow of execution may not have much bearing at all on the critical path of the application as a whole, presenting a blind spot for a sampling profiler.
Take, for instance, a multithreaded application designed to react to favorable trading signals at a financial exchange (e.g., CME or NYSE) by executing an order (e.g., BUY or SELL): a naive implementation might dedicate one thread for busy-polling the NIC to grab UDP multicast packets containing exchange market data messages which it then inserts into a software queue from which a 2nd thread pulls to process those messages looking for interesting signals, while a 3rd thread waits to be triggered to send a BUY or SELL order. The busiest, most commonly “on-CPU” instructions will derive from the 1st thread since it spins in a tight loop grabbing network packets from the NIC – as a result, a sampling profiler (e.g., Linux perf or Intel VTune or AMD uProf) will most certainly point you in that direction. However, the real aim is to ensure that the application can send an order as quickly as possible after observing a favorable signal (referred to as “tick-to-trade latency”). That code path is executed relatively infrequently, rendering sampling profilers largely ineffective. That’s where COZ comes in.
COZ is a new kind of profiler that fills the gaps left behind by traditional software profilers. It uses a novel technique called “causal profiling”, whereby experiments are conducted during the runtime of an application by virtually speeding up segments of code to predict the effect of certain optimizations. It accomplishes these “virtual speedups” by inserting pauses that slow down all other concurrently running code. It’s actually quite clever. You can read all about it here. Let’s look at an example.
I’ll use the C-Ray benchmark, which is a simple ray tracer that spawns 16 threads per core (the number of recognized cores is configurable via the NUM_CPU_CORES environment variable) to generate a 1600 x 1200 image. The target machine comprises a dual-socket Skylake Gold 6154 CPU with 36 cores running CentOS 7.3.1611. I used the OS-bundled GCCv4.85 and added the flags -g -fno-omit-frame-pointer -ldl1 to the existing compilation flags (-O3) of the install script, install.sh. I also set NUM_CPU_CORES to ‘3’ to force a longer runtime that would give COZ sufficient experimentation time. Running install.sh compiles the program and creates a Bash driver script named c-ray. I executed it as follows:
mdawson@labmach01:~$ ./c-ray
Running this command 10 times gives an average duration of 31.07 seconds.
Next, I downloaded and built COZ according to the instructions specified here. I located the function provided to each thread inside of pthread_create – it is called thread_func. Within that function, I found the loop around the workhorse function, render_scanline. Since I want to determine what optimization is necessary to execute the render_scanline function as quickly as possible, I placed the macro COZ_PROGRESS on the line directly after where render_scanline is called:
656 void *thread_func(void *tdata) {
657 int i;
658 struct thread_data *td = (struct thread_data*)tdata;
659
660 pthread_mutex_lock(&start_mutex);
661 while(!start) {
662 pthread_cond_wait(&start_cond, &start_mutex);
663 }
664 pthread_mutex_unlock(&start_mutex);
665
666 for(i=0; i<td->sl_count; i++) {
667 render_scanline(xres, yres, i + td->sl_start, td->pixels, rays_per_pixel);
668 + COZ_PROGRESS
669 }
670
671 return 0;
Then, in the c-ray Bash driver script, I prepended line 4 with coz run --- so that the full line reads:
coz run --- ./c-ray-mt -t $RT_THREADS -s 3840x2160 -r 16 -i sphfract -o output.ppm > /tmp/c-ray.out 2>&1
Upon completion of a subsequent run of the benchmark, COZ created a file named profile.coz in my current working directory – this file that contains all of COZ’s performance estimations and the source code line numbers associated with them. Here’s the output after plotting profile.coz:
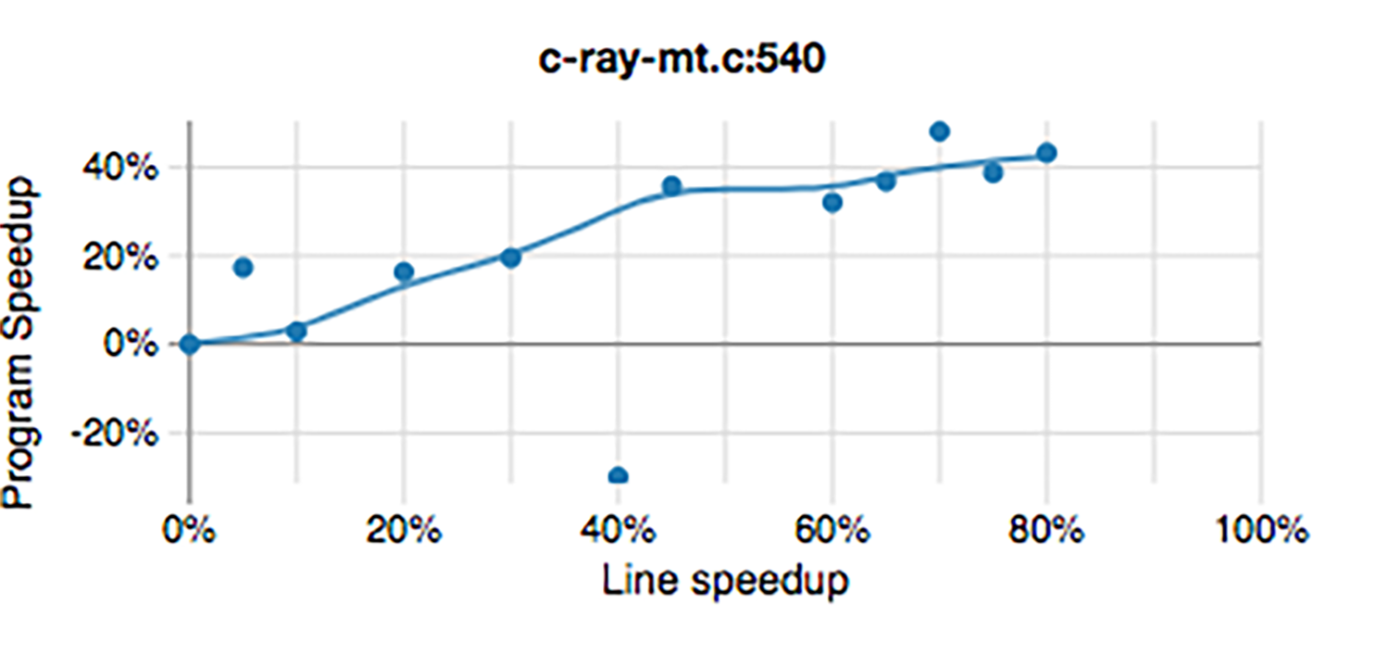
It points to line 540 in c-ray-mt.c as the prime area of focus for overall application performance. According to the graph, if we improve the performance of that line by 20%, COZ expects a corresponding increase in application performance of C-Ray benchmark overall of about 17% – once we reach ~45% improvement of that line, the impact on the application begins to level off by COZ’s estimation. Here is the line 540 of c-ray-mt.c:
525 /* Calculate ray-sphere intersection, and return {1, 0} to signify hit or no hit.
526 * Also the surface point parameters like position, normal, etc are returned through
527 * the sp pointer if it is not NULL.
528 */
529 int ray_sphere(const struct sphere *sph, struct ray ray, struct spoint *sp) {
530 double a, b, c, d, sqrt_d, t1, t2;
531
532 a = SQ(ray.dir.x) + SQ(ray.dir.y) + SQ(ray.dir.z);
533 b = 2.0 * ray.dir.x * (ray.orig.x - sph->pos.x) +
534 2.0 * ray.dir.y * (ray.orig.y - sph->pos.y) +
535 2.0 * ray.dir.z * (ray.orig.z - sph->pos.z);
536 c = SQ(sph->pos.x) + SQ(sph->pos.y) + SQ(sph->pos.z) +
537 SQ(ray.orig.x) + SQ(ray.orig.y) + SQ(ray.orig.z) +
538 2.0 * (-sph->pos.x * ray.orig.x - sph->pos.y * ray.orig.y - sph->pos.z * ray.orig.z) - SQ(sph->rad);
539
540 if((d = SQ(b) - 4.0 * a * c) < 0.0) return 0;
It’s computing a square, performing some multiplications, and a subtraction on a few doubles. What does “perf annotate” show as the generated assembly for that line?
7.01 : 401717: mulsd %xmm14,%xmm1
11.15 : 40171c: subsd %xmm1,%xmm7
9.10 : 401720: ucomisd %xmm7,%xmm12
4.68 : 401725: ja 401788 <shade+0x298>
There’s a subtraction instruction that is dependent on the preceding multiplication due to the shared register, %xmm1. This code block is screaming to be enhanced by a Fused Multiply Add (FMA) instruction – well, in this case, it would be a Fused Multiply Subtract.
I struggled to find a way to get the compiler to generate FMA only for line 540, from using a generic STDC FP_CONTRACT pragma to using a Clang-specific pragma – neither one worked for me. So, I had to add -mfma to the compiler flags, which not only replaced the assembly for line 540 with FMA but also a few other preceding lines in the same file. This makes it a bit difficult to check the predictive value of COZ’s profile.coz graph plot. Now let’s see what the generated assembly is once we compile with -mfma option:
12.82 : 4016db: vfmsub231sd %xmm1,%xmm1,%xmm0
12.10 : 4016e0: vucomisd %xmm0,%xmm10
5.55 : 4016e4: ja 401741 <shade+0x1f1>
The number of perf samples attributed to the block of assembly employing FMA is 641,916 while that of the unoptimized block amounts to 955,280 – a 33% improvement. According to the COZ graph plot, this should translate to somewhere between 20 – 30% improvement in overall application performance. When I ran with the new FMA-enabled binary, I measured a runtime duration of 23.43 seconds (vs. the original 31.07 seconds), representing a 25% improvement and a relatively accurate COZ assessment.
In this example, both COZ and Linux perf agree on the source of the bottleneck since the workload type of this benchmark lends itself well to sampling. Next time, we’ll look at a workload where perf points to code that is simply on-CPU most often yet has very little to do with the critical path performance of the application. The whitepaper “COZ: Finding Code that Counts with Causal Profiling” provides a few examples of popular opensource applications where COZ revealed critical-path bottleneck areas that were downplayed by sampling profilers.
-
Option
-ldlrequired to run COZ since it needs dlopen() to do its work. ↩
All content on Easyperf blog is licensed under a Creative Commons Attribution 4.0 International License