Understanding IDQ_UOPS_NOT_DELIVERED performance counter.
29 Dec 2018
Contents:
Subscribe to my newsletter, support me on Patreon or by PayPal donation.
It is very important to be able to characterize the application to understand it’s bottlenecks and how to improve it. By characterizing I mean tell whether we are bound by CPU front-end (we can’t fetch and decode instructions efficiently), memory (we have lots of data cache misses) or we are compute bound (say, we have a lot of expensive divisions). Modern tools are able to do this automatically thanks to particular performance monitoring counters (PMC).
PMC that we will discuss today plays very important role in top-down analysis (Intel® 64 and IA-32 Architectures Optimization Reference Manual, Appendix B.1). In this metodology we try to detect what was stalling our execution starting from the high-level components (like Front End, Back End, Retiring, Branch predictor) and narrowing down the source of performance inefficiencies.
If you’ll take a look at TMA metrics which is the heart of this metodology, first of all you’ll find that it looks very scary. :) But if you’ll look at the very first metric Frontend_Bound you’ll find formula which is used for calculating it:
Frontend_Bound = IDQ_UOPS_NOT_DELIVERED.CORE / SLOTS,
where SLOTS = Pipeline_Width * CPU_CLK_UNHALTED.THREAD,
where Pipeline_Width = 4 // for most of modern Intel architertures
Official description in this document says that Frontend_Bound “represents slots fraction where the processor’s Frontend undersupplies its Backend”. A little bit mouthful, but in simple words we can describe it as “how good we are at fetching, decoding instructions and feeding them to the rest of the pipeline”. Also mouthful, but anyway…
Mental model
In order to understand what this PMC counts let’s look at a simplified diagram:
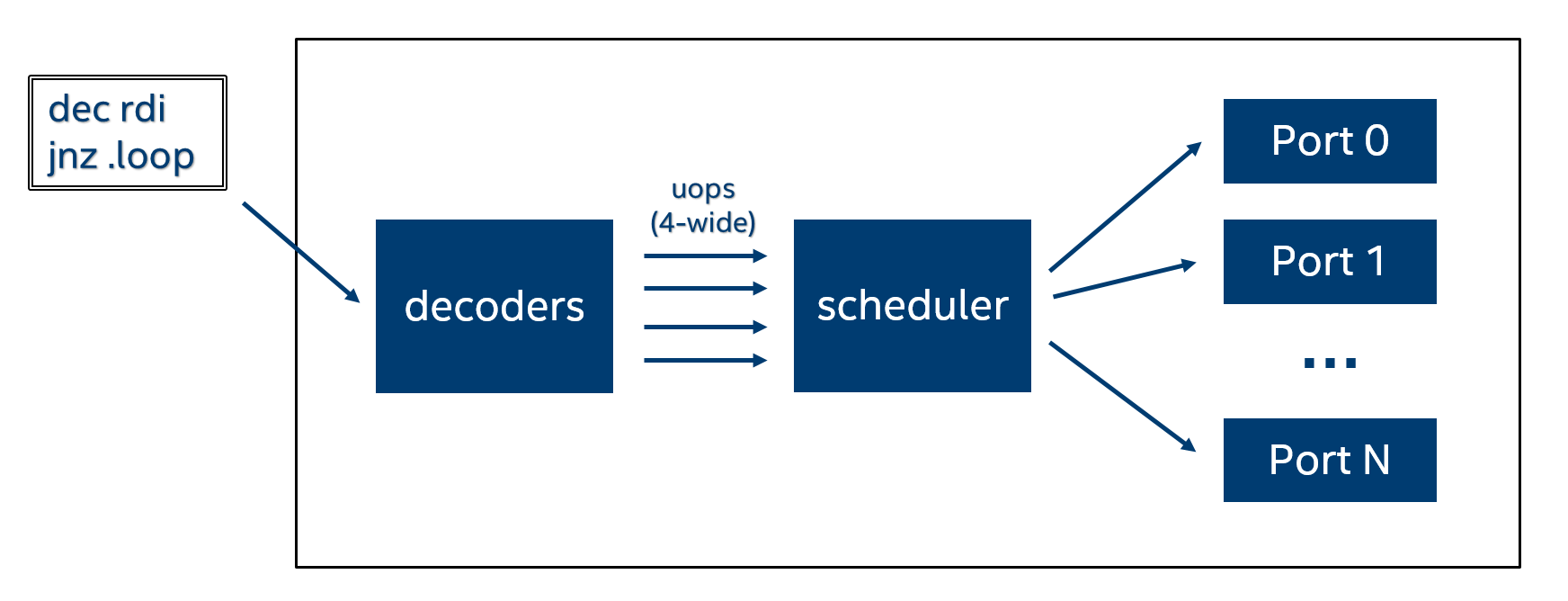
Here is the workflow:
- We fetch assembly instruction and feed it into the decoders.
- Decoders decode assembly instruction into the sequence of uops. It can be one or many uops depending on the instruction.
- Then scheduler sends them into the back-end for execution.
Because we have multiple execution units we can execute multiple uops in parallel. Most of modern Intel CPUs are 4-wide, meaning that we can schedule 4 uops each cycle. But it usually happens that due to some hazards (data dependency/execution unit occupied/lack of uops to schedule) we can’t fully utilize all available slots and, say, issue only 3 uops.
We can have a counter that will keep track of how many slots we failed to utilize. So if, let’s say, we deliver only 1 uop this counter will be increased by 3 (it’s basically 4 – 1 is 3). If we deliver 4 uops in one cycle it will not be increased because we did a good job of filling all available slots. As you already guessed the lower the value for this counter, the better.
In reality CPU is much more complicated than this and there is IDQ (Instruction Decode Queue) and RAT (Resource Allocation Table). Our PMC IDQ_UOPS_NOT_DELIVERED.CORE counts the number of uops not delivered from IDQ to RAT and RAT is not stalled. I hope it will become more clear once you’ll go through examples (see below). I will not describe how IDQ and RAT interoperate because this goes beyond the topic of this article. For us it’s just important to understand that there is a “bridge” from CPUs front end to the back end and we have means to monitor it.
Example 1
I made a simple example with “ideal” loop where in each cycle we utilize all 4 available slots:
mov rdx, 1000000000
.loop:
inc rcx
inc rsi
inc rdi
dec rdx
jnz .loop
All measurements were done on Skylake CPU.
$ perf stat -e instructions,cycles,cpu/event=0x9c,umask=0x1,name=IDQ_UOPS_NOT_DELIVERED.CORE/ -- ./a.out
Performance counter stats for './a.out':
5001750626 instructions # 4,96 insn per cycle
1009211538 cycles
1429415 IDQ_UOPS_NOT_DELIVERED.CORE
Code and build script are available on my github.
Notice, our loop is 5 instructions/4 uops per iteration, because dec+jnz pair was MacroFused into a single uop. Also notice, amount of IDQ_UOPS_NOT_DELIVERED.CORE is negligible comparing to the number of cycles executed.
Our Front-End boundness metric will be:
Frontend_Bound = IDQ_UOPS_NOT_DELIVERED.CORE / (4 * cycles) = 1429415 / (4 * 1009211538) = 0.03 %
We can say that this case is ideal from the Front End bound point of view. Everything fits nicely in the pipeline and we are able to issue 4 uops each cycle. I also confirmed that by collecting LSD.CYCLES_ACTIVE and LSD.CYCLES_4_UOPS:
$ perf stat -e cycles,cpu/event=0xA8,umask=0x01,cmask=0x1,name=LSD.CYCLES_ACTIVE/,cpu/event=0xA8,umask=0x01,cmask=0x4,name=LSD.CYCLES_4_UOPS/ -- ./a.out
Performance counter stats for './a.out':
1018747105 cycles
994491346 LSD.CYCLES_ACTIVE
994490536 LSD.CYCLES_4_UOPS
This tells us that LSD delivered 4 uops every cycle.
It may look easy when things get ideal but it becomes quite complicated to analyze when there are stalls in the pipeline. Let’s look at such example.
Example 2
The dummy loop of 2 instructions/1 uop per iteration (again, dec+jnz pair was MacroFused into a single uop):
mov rdx, 1000000000
.loop:
dec rdx
jnz .loop
$ perf stat -e instructions,cycles,cpu/event=0x9c,umask=0x1,name=IDQ_UOPS_NOT_DELIVERED.CORE/ -- ./a.out
Performance counter stats for './a.out':
2001858013 instructions # 2,00 insn per cycle
1001933752 cycles
1012451532 IDQ_UOPS_NOT_DELIVERED.CORE
According to our mental model we should be wasting 3 slots to deliver uops to RAT each cycle. We have 10^9 cycles, so the number for IDQ_UOPS_NOT_DELIVERED.CORE should be somewhere around 3 * 10^9, but it’s not. It’s much less in this case because the RAT itself was stalled (remember, IDQ_UOPS_NOT_DELIVERED.CORE only gets increased when the backend is requesting uops) during some amount of cycles and was not able to take uops:
Performance counter stats for './a.out':
1007893869 cycles
505674623 UOPS_ISSUED.STALL_CYCLES
503135956 LSD.CYCLES_ACTIVE
232128 LSD.CYCLES_4_UOPS
We can see that half of the time RAT was stalled (likely because it was full) and another half of the time LSD was active and delivered some amount of uops. We can already guess that number because we know how many total slots we wasted (IDQ_UOPS_NOT_DELIVERED.CORE). Each second cycle LSD delivered 2 uops which also means that each second cycle IDQ_UOPS_NOT_DELIVERED.CORE was increased by 2. Given that the number of cycles the backend was requesting uops is 5 * 10^8 and we wasted 2 slots on each of them, we confirmed the number for IDQ_UOPS_NOT_DELIVERED.CORE (10^9).
I must say that I expected to see one uop delivered each cycle instead of 2 uops each second cycle. I’m not entirely sure why that’s the case. It proves that real CPU design is much more complicated than my mental model. :)
UPD: Travis Downs in the comments provided his measurements when LSD is disabled. There he shows that if the loops is served out of DSB we have 3 “uops not delivered” per cycle. See comments for more details.
Another way to do this is to use subcounters of IDQ_UOPS_NOT_DELIVERED:
- IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOP_DELIV.CORE - Cycles which 4 issue pipeline slots had no uop delivered from the front end to the back end when there is no back-end stall.
- IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_n_UOP_DELIV.CORE - Cycles which “4-n” issue pipeline slots had no uop delivered from the front end to the back end when there is no back-end stall.
- IDQ_UOPS_NOT_DELIVERED.CYCLES_FE_WAS_OK - Cycles which front end delivered 4 uops or the RAT was stalling FE
Performance counter stats for './a.out':
1002271977 cycles (83,33%)
286803 IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOP_DELIV.CORE (83,33%)
6248629 IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_1_UOP_DELIV.CORE (83,33%)
503382522 IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_2_UOP_DELIV.CORE (83,33%)
503531042 IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_3_UOP_DELIV.CORE (83,33%)
500685038 IDQ_UOPS_NOT_DELIVERED.CYCLES_FE_WAS_OK (66,77%)
Looking at those numbers we can say how many cycles we were delivering specific number of uops to the RAT (and there is no back-end stall):
Cycles with 0 uop delivered = IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOP_DELIV.CORE
Cycles with 1 uop delivered = IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_1_UOP_DELIV.CORE - IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOP_DELIV.CORE
Cycles with 2 uop delivered = IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_2_UOP_DELIV.CORE - IDQ_UOPS_NOT_DELIVERED.CYCLES_1_UOP_DELIV.CORE
Cycles with 3 uop delivered = IDQ_UOPS_NOT_DELIVERED.CYCLES_LE_3_UOP_DELIV.CORE - IDQ_UOPS_NOT_DELIVERED.CYCLES_2_UOP_DELIV.CORE
Cycles with 4 uop delivered = IDQ_UOPS_NOT_DELIVERED.CYCLES_FE_WAS_OK
In our case it’s:
Cycles with 0 uop delivered = 286803
Cycles with 1 uop delivered = 5961826
Cycles with 2 uop delivered = 497133893
Cycles with 3 uop delivered = 148520
Cycles with 4 uop delivered = 500685038
If we sum up all those numbers we will receive the number of cycles spent. I’m pretty sure we haven’t delivered 4 uops not a single cycle, it’s just that the backend was stalled during that time, that’s why we have such a big number for IDQ_UOPS_NOT_DELIVERED.CYCLES_FE_WAS_OK.
Conclusion
Here you have useful tool which you can use to better understand performance issues you might have. It’s very interesting to see sometimes cases where just making small changes makes a huge impact on IDQ_UOPS_NOT_DELIVERED counters.
For big applications it’s impossible to reason about the execution pattern of the benchmark just by looking at IDQ_UOPS_NOT_DELIVERED counters, but it might give you some interesting insights and further direction. When you made some changes in your application and want to analyze the effect, it’s sometimes fruitful to compare the absolute numbers for IDQ_UOPS_NOT_DELIVERED counters. However, there should be a strong difference, couple of percents do not count. For particular application of using this counter take a look at my post Code alignment issues.
Nowadays, when I’m doing benchmarking I run the binaries by default under perf stat -e IDQ_UOPS_NOT_DELIVERED.CORE. Because it not only gives you the execution time, it also collects performance counters and it’s almost free (when there is no multiplexing between counters).
All content on Easyperf blog is licensed under a Creative Commons Attribution 4.0 International License