Advanced profiling topics. PEBS and LBR.
08 Jun 2018
Contents:
- Multiplexing and scaling events
- Runtime overhead of characterizing and profiling
- Interrupt- vs. event-based sampling
- Processor Event-Based Sampling (PEBS)
- Last Branch Record (LBR)
- Other resources:
Subscribe to my newsletter, support me on Patreon or by PayPal donation.
In my previous post I made an overview of what PMU (Performance Monitoring Unit) is and what is PMU counter (PMC). We learned that there are fixed and programmable PMCs inside each PMU. We explored basics of counting and sampling mechanisms and left off on the advanced techniques and features for sampling.
To recap, previously I showed the number of steps which profiling tool does in order to collect statictics for your application. We initialize the counter with some number and wait until it overflows. On counter overflow, the kernel records information, i.e., a sample, about the execution of the program. What gets recorded depends on the type of measurement, but the key information that is common in all samples is the instruction pointer, i.e. where was the program when it was interrupted.
Multiplexing and scaling events
The topic of multiplexing between different events in runtime is covered pretty well here, so I decided to take most of the explanation from it.
If there are more events than counters, the kernel uses time multiplexing to give each event a chance to access the monitoring hardware. With multiplexing, an event is not measured all the time. At the end of the run, the tool scales the count based on total time enabled vs time running. The actual formula is:
final_count = raw_count * ( time_running / time_enabled )
For example, say during profiling we were able to measure counter that we are interested 5 times, each measurement interval lasted 100ms (time_enabled). The program executed time is 1s(time_running). Total number of events for this counter is 10000 (raw_count). So, the final_count will be equal to 20000.
This provides an estimate of what the count would have been, had the event been measured during the entire run. It is very important to understand that this is an estimate not an actual count. Depending on the workload, there will be blind spots which can introduce errors during scaling.
This pretty much explains how “general-exploration” analysis in Intel VTune Amplifier is able to collect near 100 different events just in single execution of the programm. For callibrating purposes, profiling tools usually have thresholds for different counters to decide if we can trust the measured number of events, or it is too low to rely on (see MUX reliability).
The easiest algorithm for multiplexing events is to manage it in round-robin fashion. Therefore each event will eventually get a chance to run. If there are N counters, then up to the first N events on the round-robin list are programmed into the PMU. In certain situations it may be less than that because some events may not be measured together or they compete for the same counter.
To avoid scaling, one can try to reduce the number of events to be not bigger than the amount of physical PMCs available.
Runtime overhead of characterizing and profiling
On the topic of runtime overhead in counting and sampling modes there is a very good paper written by A. Nowak and G. Bitzes. They measured profiling overhead on a Xeon-based machine with 48 logical cores in different configurations: with disabled/enabled Hyper Threading, running tasks on all/several/one cores and collecting 1/4/8/16 different metrics.
In my interpretation there is almost no runtime overhead (1-2%%) in counting mode. In sampling mode it’s cheap unless you don’t multiplex between different counters (and keep sampling frequency not too high). However, if you’ll try to collect more counters than the physical PMU counters available, you’ll get performance hit of about 5-15% depending on the number of counters you want to collect. Finally, the higher is the sampling frequency the bigger is the overhead of profiling, as more interrupts need to be processed.
Interrupt- vs. event-based sampling
Interrupt-based sampling can be described as a simple process in which when the counter overflows, processor triggers the performance interrupt.
Interrupt-based sampling introduces skids on modern processors. That means that the instruction pointer stored in each sample designates the place where the program was interrupted to process the PMU interrupt, not the place where the counter actually overflows, i.e., where it was at the end of the sampling period. In some case, the distance between those two points may be several dozen instructions or more if there were taken branches.
Let’s take a look at the example:
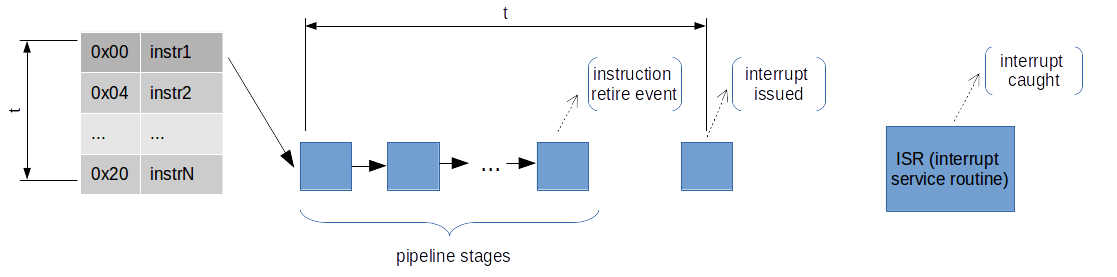 UPD: Read more details in great article about interrupts by Travis Down.
UPD: Read more details in great article about interrupts by Travis Down.
Let’s assume that on retirement of instr1 we have an overflow of the counter that samples “instruction retired” events. Because of latency in the microarchitecture between the generation of events and the generation of interrupts on overflow, it is sometimes difficult to generate an interrupt close to an event that caused it. So by the time the interrupt is generated our IP has gone further by a number of instructions. When we reconstruct register state in interrupt service routine, we have slightly inaccurate data.
Processor Event-Based Sampling (PEBS)
The problem with the skids is possible to mitigate by having the processor itself store the instruction pointer (along with other information) in a designated buffer in memory – no interrupts are issued for each sample and the instruction pointer is off only by a single instruction, at most. This needs to be supported by the hardware, and is typically available only for a subset of supported events – this capability is called Processor Event-Based Sampling (PEBS) on Intel processors. You can also see people call it Precise Event-Based Sampling, but according to Intel manuals, first word is “Processor” not “Precise”. But it basically means the same thing.
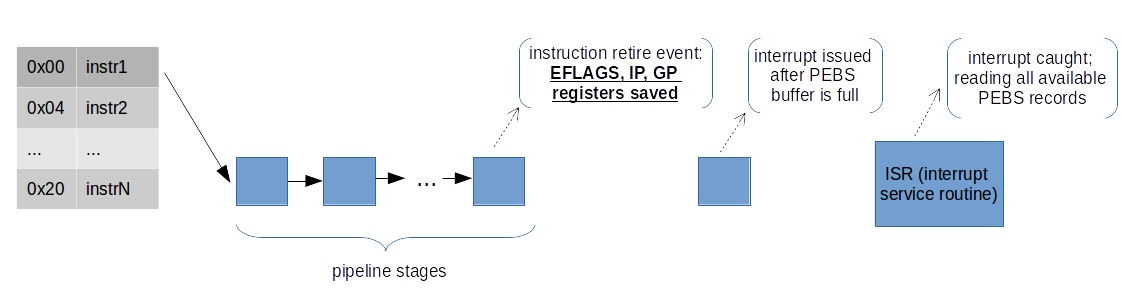
When a counter is enabled to capture machine state, the processor will write machine state information to a memory buffer specified by software. When the counter overflows from maximum count to zero, the PEBS hardware is armed. Upon occurrence of the next PEBS event, the PEBS hardware triggers an assist and causes a PEBS record to be written into the PEBS buffer. This record contains the architectural state of the processor (state of the general purpose registers, EIP register, and EFLAGS register). With PEBS, the format of the samples is mandated by the processor, so the best way to know it is to look into the Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3B, Chapter 18.
Not all events support PEBS. For example, on Sandy Bridge there are 7 PEBS events supported:
- INST_RETIRED
- UOPS_RETIRED
- BR_INST_RETIRED
- BR_MISP_RETIRED
- MEM_UOPS_RETIRED
- MEM_LOAD_UOPS_RETIRED
- MEM_LOAD_UOPS_LLC_HIT_RETIRED
PEBS events for patricular architecture can be checked in Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3B, Chapter 18.
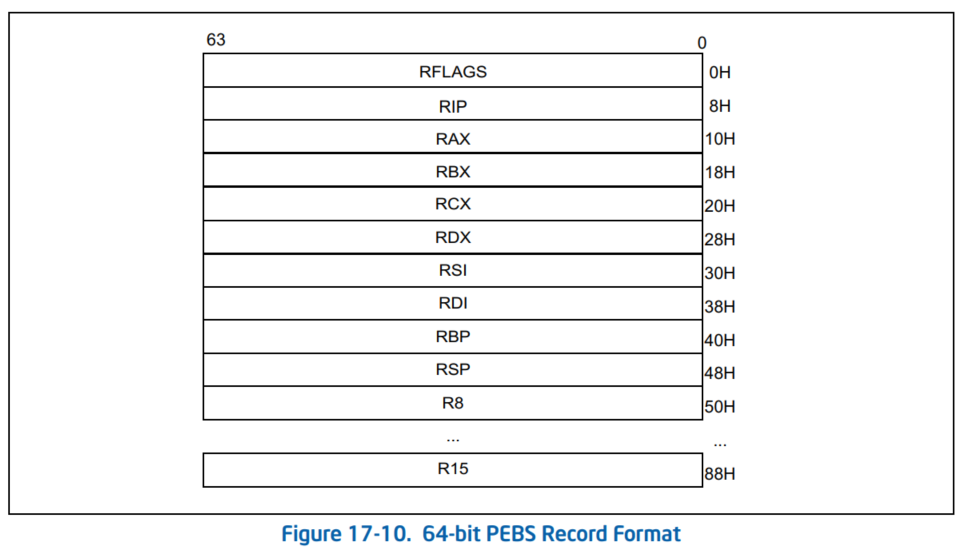
PEBS buffer consists of records. Each sample contains the machine state of the processor at the time the counter overflowed. Here is the example of PEBS record (picture below is taken from Intel manual):
You can check if PEBS are enabled by executing dmesg right after startup:
$ dmesg | grep PEBS
[ 0.061116] Performance Events: PEBS fmt1+, IvyBridge events, 16-deep LBR, full-width counters, Intel PMU driver.
You can use PEBS with perf by adding :p and :pp suffix to the event specifier:
perf record -e event:pp
Benefits of using PEBS:
- The skid is mimized compared to regular interrupted instruction pointer.
- Reduce the overhead because the Linux kernel is only involved when the PEBS buffer fills up, i.e., there is no interrupt until a lot of samples are available.
Last Branch Record (LBR)
There is a great series on the topic of LBR and it’s applications on lwm.net by Andi Kleen:
Intel CPUs have a feature called last branch records (LBR) where the CPU can continuously log branches to a set of model-specific registers (MSRs). The CPU hardware can do this in parallel while executing the program without causing any slowdown. There is some performance penalty for reading these registers, however.
The LBRs log the “from” and “to” address of each branch along with some additional metadata. The registers act like a ring buffer that is continuously overwritten and provides only the most recent entries. There is also a TOS (top of stack) register to provide a pointer to the most recent branch. With LBRs we can sample branches, but during each sample look at the previous 8-32 branches that were executed. This gives reasonable coverage of the control flow in the hot code paths, but does not overwhelm us with too much information, as only a smaller number of the total branches are examined.
Once we are able to sample LBRs it is possible to set up sampling of branch events at a frequency that does not slow down the workload unduly, and still create an useful histogram of hot branches. It is important to keep in mind that this is still sampling, so not every executed branch can be examined. CPUs generally execute too fast for that to be feasible.
The last branch recording mechanism tracks not only branch instructions (like JMP, Jcc, LOOP and CALL instructions), but also other operations that cause a change in the instruction pointer (like external interrupts, traps and faults). The branch recording mechanisms generally employs a set of MSRs (Model Specific Registers), referred to as last branch record (LBR) stack. The size and exact locations of the LBR stack are generally model-specific. The picture below is taken from Intel® 64 and IA-32 Architectures Optimization Reference Manual, Chapter B.3.3.4:

Last Branch Record (LBR) Stack — The LBR consists of N pairs of MSRs (N is, again, model specific) that store source and destination address of recent branches. Last Branch Record Top-of-Stack (TOS) Pointer — contains a pointer to the MSR in the LBR stack that contains the most recent branch, interrupt, or exception recorded.
There are two important usages for LBR as mentioned in Intel® 64 and IA-32 Architectures Optimization Reference Manual, Chapter B.3.3.4:
- Collecting Call Counts and Function Arguments. If the LBRs are captured for PMIs triggered by the BR_INST_RETIRED.NEAR_CALL event, then the call count per calling function can be determined by simply using the last entry in LBR. As the PEBS IP will equal the last target IP in the LBR, it is the entry point of the calling function. Similarly, the last source in the LBR buffer was the call site from within the calling function. If the full PEBS record is captured as well, then for functions with limited numbers of arguments on 64-bit OS’s, you can sample both the call counts and the function arguments.
- Basic Block Execution Counts. This is rather complicated to explain, so I refer a reader for the manual to read more about this.
- UPD: Precise timing of machine code.
- UPD: Estimating branch probability.
From a user perspective LBR can be used for collecting call-graph information even if you compiled your app without frame pointers (controlled by compiler option ‘-fomit-frame-pointer’, ON by default):
$ perf record --call-graph lbr
Using LBR in perf also allows you to see where were the most amount of branches:
$ perf record -b
For some more applications of LBR, including debugging support and hot-path branch history, you can take a look at Andi Kleen’s articles on lwn.net: part1, part2.
Other resources:
- Presentation on Black Hat 2015 conference by N. Herath and A. Fogh “These are Not Your Grand Daddy’s CPU Performance Counters”: video, slides
- Brendan Gregg’s article about perf
- Linux kernel profiling with perf tutorial
- Somewhat old, but still actual guide on how to program PMU: Nehalem Performance Monitoring Unit Programming Guide
- Description of instructions:
RDPMC, RDTSC, RDTSCP, RDMSR, WRMSRin Intel SDM v2, Instruction Set Reference
All content on Easyperf blog is licensed under a Creative Commons Attribution 4.0 International License